L’analisi dei dati è diventata una parte fondamentale del business moderno. Grazie ai progressi tecnologici negli algoritmi di machine learning e deep learning, possiamo elaborare estrarre informazioni utili dai dati aziendali.
In questo articolo, esploreremo come gli algoritmi di deep learning possono essere utilizzati per risolvere un caso aziendale reale.
L’obiettivo del nostro esempio sarà quello di prevedere se un cliente lascerà l’azienda o meno. Abbiamo raccolto i dati sui nostri clienti e vogliamo utilizzarli per costruire un modello di deep learning che possa prevedere se un cliente andrà via o rimarrà con l’azienda.
Di seguito le prime 20 righe del dataset:
RowNumber,CustomerId,Surname,CreditScore,Geography,Gender,Age,Tenure,Balance,NumOfProducts,HasCrCard,IsActiveMember,EstimatedSalary,Exited
1,15634602,Hargrave,619,France,Female,42,2,0.00,1,1,1,101348.88,1
2,15647311,Hill,608,Spain,Female,41,1,83807.86,1,0,1,112542.58,0
3,15619304,Onio,502,France,Female,42,8,159660.80,3,1,0,113931.57,1
4,15701354,Boni,699,France,Female,39,1,0.00,2,0,0,93826.63,0
5,15737888,Mitchell,850,Spain,Female,43,2,125510.82,1,1,1,79084.10,0
6,15574012,Chu,645,Spain,Male,44,8,113755.78,2,1,0,149756.71,1
7,15592531,Bartlett,822,France,Male,50,7,0.00,2,1,1,10062.80,0
8,15656148,Obinna,376,Germany,Female,29,4,115046.74,4,1,0,119346.88,1
9,15792365,He,501,France,Male,44,4,142051.07,2,0,1,74940.50,0
10,15592389,H?kansson,684,France,Male,27,2,134603.88,1,1,1,71725.73,0
11,15767821,Bearce,528,France,Male,31,6,102016.72,2,0,0,80181.12,0
12,15737173,Andrews,497,Spain,Male,24,3,0.00,2,1,0,76390.01,0
13,15632264,Kay,476,France,Female,34,10,0.00,2,1,0,26260.98,0
14,15691483,Chin,549,France,Female,25,5,0.00,2,0,1,190857.79,0
15,15600882,Scott,635,Spain,Female,35,7,0.00,2,1,1,65951.65,0
16,15643966,Goforth,616,Germany,Male,45,3,143129.41,2,0,1,64327.26,0
17,15737452,Romeo,653,Germany,Male,58,1,132602.88,1,1,0,5097.67,1
18,15788218,Henderson,549,Spain,Female,24,9,0.00,2,1,1,14406.41,0
19,15661507,Muldrow,587,Spain,Male,45,6,0.00,1,0,0,158684.81,0
20,15568982,Hao,726,France,Female,24,3,0.00,5,1,1,50984.05,0
Il dataset ha diverse variabili come l’età del cliente, il suo reddito, il tempo che ha trascorso con l’azienda, il numero di prodotti acquistati e altri. La variabile target è se il cliente ha abbandonato l’azienda o no (Exited).
Il dataset è possibile scaricarlo al seguente indirizzo:
https://www.kaggle.com/code/ahmetcankaraolan/churn-prediction-using-machine-learning/input
Il primo passo consiste nell’importare le librerie necessarie per la lettura e la manipolazione dei dati. Viene utilizzata la libreria Pandas per la lettura del dataset e la libreria Scikit-learn per la normalizzazione dei dati e la creazione del set di training e di testing. Inoltre, vengono importate le librerie di Keras per la definizione, la compilazione e l’addestramento del modello di Deep Learning.
from sklearn.preprocessing import RobustScaler
from imblearn.combine import SMOTETomek
import numpy as np
from sklearn.metrics import accuracy_score
from keras.optimizers import Adam
from keras.layers import Dense
from keras.models import Sequential
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import pandas as pdViene quindi impostato il display di Pandas per mostrare tutte le colonne del dataset.
pd.set_option('display.max_columns', None)
Il dataset viene letto dal file “customer_churn.csv” utilizzando la funzione read_csv() della libreria Pandas.
# lettura del dataset da file
df = pd.read_csv('customer_churn.csv')
Successivamente, vengono cancellati tutti i valori mancanti nel dataset utilizzando la funzione dropna() della libreria Pandas.
# Cancellazione valori mancanti
df.dropna(inplace=True)
Vengono poi create nuove colonne che rappresentano feature ingegnerizzate. La prima colonna rappresenta la differenza tra l’età del cliente e il periodo in cui è stato cliente dell’azienda. Le altre colonne vengono create suddividendo i valori di alcune colonne in diversi intervalli usando la funzione pd.qcut().
# features engineriing
df["NewAGT"] = df["Age"] - df["Tenure"]
df["CreditsScore"] = pd.qcut(df['CreditScore'], 10, labels=[
1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
df["AgeScore"] = pd.qcut(df['Age'], 8, labels=[1, 2, 3, 4, 5, 6, 7, 8])
df["BalanceScore"] = pd.qcut(df['Balance'].rank(
method="first"), 10, labels=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
df["EstSalaryScore"] = pd.qcut(df['EstimatedSalary'], 10, labels=[
1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
df["NewEstimatedSalary"] = df["EstimatedSalary"] / 12Le feature vengono poi trasformate utilizzando la tecnica di one-hot encoding per convertire i dati categorici in numerici.
# one-hot encoding
df = pd.get_dummies(df, columns=["Geography", "Gender"], drop_first=True)Successivamente eseguiamo la rimozione delle colonne “CustomerId” e “Surname” dal dataframe, utilizzando il metodo drop e specificando l’argomento axis=1 per indicare che si vuole eliminare le colonne e non le righe.
Successivamente, viene creato un nuovo dataframe cat_df contenente solo alcune colonne specifiche, ovvero “Geography_Germany”, “Geography_Spain”, “Gender_Male”, “HasCrCard” e “IsActiveMember”.
Inoltre, vengono definiti i dataframe X e y, dove y rappresenta la variabile target “Exited” e X rappresenta tutte le altre variabili tranne quelle presenti in cat_df. Infine, vengono salvate le colonne e gli indici del dataframe X.
Il metodo RobustScaler() viene poi utilizzato per standardizzare i dati nel dataframe X, e il risultato viene salvato in un nuovo dataframe X di tipo pd.DataFrame. La concatenazione tra X e cat_df viene infine eseguita utilizzando il metodo concat, specificando axis=1 per unire i due dataframe lungo le colonne.
df = df.drop(["CustomerId", "Surname"], axis=1)
cat_df = df[["Geography_Germany", "Geography_Spain",
"Gender_Male", "HasCrCard", "IsActiveMember"]]
y = df["Exited"]
X = df.drop(["Exited", "Geography_Germany", "Geography_Spain",
"Gender_Male", "HasCrCard", "IsActiveMember"], axis=1)
cols = X.columns
index = X.index
transformer = RobustScaler().fit(X)
X = transformer.transform(X)
X = pd.DataFrame(X, columns=cols, index=index)
X = pd.concat([X, cat_df], axis=1)
Successivamente, il dataset viene diviso in training set e test set utilizzando la funzione “train_test_split” della libreria Sklearn. La percentuale di dati utilizzata per il test set è del 20%.
# suddivisione del dataset in training set e test set
# la funzione train_test_split divide casualmente il dataset in training set e test set
# il parametro test_size specifica la percentuale di dati da utilizzare per il test set
# random_state garantisce la riproducibilità dei risultati
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0)Viene poi definito un modello di deep learning utilizzando la libreria Keras. Il modello ha tre strati: il primo strato ha 32 neuroni e utilizza la funzione di attivazione “relu”, il secondo strato ha 16 neuroni e utilizza la funzione di attivazione “relu” e l’ultimo strato ha un neurone e utilizza la funzione di attivazione “sigmoid”.
# Definizione del modello
model = Sequential()
model.add(Dense(32, input_dim=18, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
Dopo aver definito il modello, dobbiamo compilarlo specificando la funzione di loss da minimizzare, l’ottimizzatore e le metriche da monitorare durante l’addestramento. In questo caso, usiamo la funzione di loss binary_crossentropy, l’ottimizzatore Adam con un learning rate di 0.001 e la metrica di accuracy.
# Compilazione del modello
optimizer = Adam(learning_rate=0.001)
model.compile(loss='binary_crossentropy',
optimizer=optimizer, metrics=['accuracy'])
Ora che il modello è stato compilato, possiamo addestrarlo sui dati utilizzando il metodo fit di Keras. In questo esempio, addestreremo il modello per 100 epoche (cioè 100 iterazioni attraverso tutti i dati di addestramento) e utilizzeremo un batch size di 10 (cioè addestreremo il modello su 10 campioni alla volta).
# Addestramento del modello
model.fit(X_train, y_train, epochs=100, batch_size=10)
Una volta addestrata la rete neurale, possiamo utilizzarla per fare predizioni sui dati di test. In questo esempio, useremo il metodo predict di Keras per fare le previsioni.
# Predizione sui dati di test
y_pred = model.predict(X_test)
Infine, valutiamo le prestazioni del modello utilizzando la metrica di accuracy e stampiamo il risultato.
cvscores = []
scores = model.evaluate(X_test, y_test, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
Inoltre, abbiamo definito la funzione stampa_previsioni
def stampa_previsioni(previsioni):
y_pred = previsioni
Y_pred = []
i = 0
for y in y_test:
if y_pred[i] > 0.5:
pred = 1
else:
pred = 0
Y_pred.append(pred)
if y == 1:
risultato = 'a'
else:
risultato = 'na'
if pred == 1:
previsione = 'a'
else:
previsione = 'na'
if i <= 50:
print(' R: ', risultato, ' P: ', previsione)
i = i + 1
return Y_predche prende in input un array di previsioni del modello e restituisce un array di etichette di classe binarie (0 o 1) basate su una soglia di decisione di 0,5. Questa funzione viene utilizzata per stampare le previsioni e le etichette di classe corrispondenti per i primi 50 dati di test.
il risultato è il seguente:
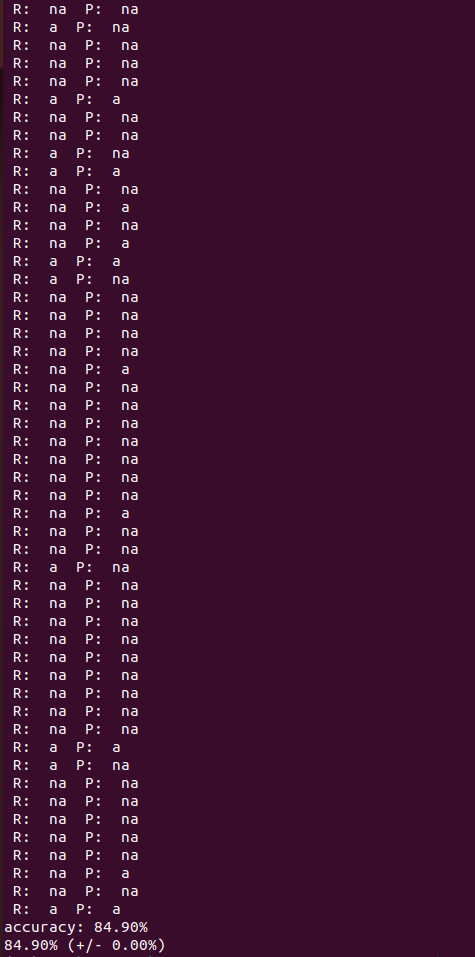
Come si vede, utilizzando la funzione stampa_previsioni è possibile confrontare i risultati (R) con le previsioni (P) tenendo presente che na vuol dire “non abbandona” mentre a sta per “abbandona.
Con un addestramento di 100 epoche e senza ottimizzare particolarmente l’algoritmo di deep learning si riesce comunque ad ottenere un’accuracy di quasi l’85%. Niente male!
In conclusione, l’utilizzo di algoritmi di deep learning come il Neural Network può essere estremamente utile per risolvere problemi aziendali complessi come la predizione dell’abbandono dei clienti. Nel nostro esempio, abbiamo mostrato come un modello di deep learning basato su una rete neurale artificiale possa essere addestrato per analizzare grandi quantità di dati e predire in modo accurato il churn dei clienti. Ciò consente alle aziende di prendere decisioni informate sulla fidelizzazione dei clienti e sulle strategie di marketing.
Infine, è importante sottolineare che l’utilizzo di algoritmi di deep learning richiede un’adeguata conoscenza delle tecniche di machine learning, nonché la capacità di elaborare grandi quantità di dati e di analizzare i risultati del modello. Pertanto, se siete interessati ad utilizzare algoritmi di deep learning nella vostra azienda, è consigliabile rivolgersi a professionisti esperti nel campo del machine learning.